耿雨飞的个人博客
首页
文章搜索
人工智能
项目相关
首页
文章搜索
人工智能
项目相关
登录
注册
[[ slide_text ]]
[[ item.c ]]
0
0
K8s 核心概念
发布时间:
2023-05-04
作者:
gengyufei
来源:
gengyufei个人博客
Kubernetes
# pod ## 概述 - Pod 是在 Kubernetes 集群中**运行部署应用或服务的最小单元(即:最小的管理单元)**,它是可以**支持多容器**的。 - Pod 的**设计理念**是支持多个容器在一个 Pod 中**共享网络地址和文件系统**,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。 - **Pod 是** Kubernetes 集群中**所有业务类型的基础** - 目前 Kubernetes 中的业务主要可以分为: **长期伺服型**(long-running)、**批处理型**(batch)、**节点后台支撑型**(node-daemon)和**有状态应用型**(stateful application);分别对应的控制器为 Deployment、Job、DaemonSet 和 StatefulSet - Kubernetes为**每个Pod**都分配了**唯一的IP地址**,称之为**Pod IP**,**一个Pod里的多个容器共享Pod IP地址**,Kubernetes**底层网络支持**集群内**任意两个Pod之间的TCP/IP直接通信**,这通常采用**虚拟二层网络技术来实现**,例如Flannel、Open vSwitch等,因此我们需要**牢记一点**:**在Kubernetes里,一个Pod里的容器与另外主机上的Pod容器能够直接通信** - Pod有**两种类型**:**普通的Pod**及**静态Pod**(Static Pod),后者比较特殊,它并不存放在Kubernetes的etcd存储里,而是存放在某个**具体的Node上的一个具体文件中**,并且只在此Node上启动运行 ## pod、node 及 容器的关系  ## pod yaml定义demo ``` apiVersion: v1 kind: Pod metadata: name: myweb spec: containers: - name: myweb image: tomcat:9.0.53-jdk8-openjdk ports: - containerPort: 8080 env: - name: MYSQL_SERVICE_HOST value: 'mysql' - name: MYSQL_SERVICE_PORTT value: '3306' ``` - metadata里还能定义资源对象的标签(Label),这里表明myweb拥有一个name=myweb的标签(Label) - Pod的IP加上这里的容器端口(containerPort),就组成了一个新的概念 -- Endpoint,它代表着此**Pod里的一个服务进程的对外通信地址** ## pod 资源配额 每个Pod都可以对其能使用的服务器上的**计算资源设置限额**,当前可以设置限额的计算资源有**CPU与Memory**两种,其中**CPU的资源单位为CPU(Core)的数量,是一个绝对值而非相对值**。 **一个CPU的配额对于绝大多数容器来说是相当大的一个资源配额**了,所以,在Kubernetes里,通常**以千分之一的CPU配额为最小单位,用m来表示**。通常一个容器的CPU配额被定义为100~300m,即占用0.1~0.3个CPU。由于CPU配额是一个绝对值,所以无论在拥有一个Core的机器上,还是在拥有48个Core的机器上,100m这个配额所代表的CPU的使用量都是一样的。与CPU配额类似,**Memory配额也是一个绝对值,它的单位是内存字节数**。 在Kubernetes里,一个计算资源进行配额限定需要设定以下两个参数。 - Request:该资源的最小申请量,系统必须满足要求。 - Limits:该资源最大允许使用量,不能被突破,当容器试图使用超过这个量的资源时,可能会被Kubernetes Kill并重启。 通常我们会把**Request设置为一个比较小的数值**,符合容器平时的工作负载情况下的资源需求,而**把Limit设置为负载均衡情况下资源占用的最大量**。比如下面这些定义,表明MySQL容器申请最少0.25个CPU及64MiB内存,在运行过程中MySQL容器所能使用的资源配额最大为0.5个CPU及128MiB内存: ``` spec: containers: - name: db image: mysql resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" ``` # Label 标签 ## 概述 - Label是Kubernetes系统中另外一个核心概念 - 一个Label是一个key=value的键值对,其中key与vaue由用户自己指定 - 用于灵活、方便地进行资源分配、调度、配置、部署等管理工作 ## 常用 Label - 版本标签:"release" : "stable" , "release" : "canary"... - 环境标签:"environment" : "dev" , "environment" : "production" - 架构标签:"tier" : "frontend" , "tier" : "backend" , "tier" : "middleware" - 分区标签:"partition" : "customerA" , "partition" : "customerB"... - 质量管控标签:"track" : "daily" , "track" : "weekly" ## 案例 以myweb Pod为例,Label定义在其metadata中: ``` apiVersion: v1 kind: Pod metadata: name: myweb labels: app: myweb ``` 管理对象RC和Service在spec中定义Selector与Pod进行关联: ``` apiVersion: v1 kind: ReplicationController metadata: name: myweb spec: replicas: 1 selector: app: myweb template: ...略... apiVersion: v1 kind: Service metadata: name: myweb spec: selector: app: myweb ports: - port: 8080 ``` ## 基于集合的 label selector 基于集合的筛选条件定义,例如: ``` selector: matchLabels: app: myweb matchExpressions: - {key: tier, operator: In, values: [frontend]} - {key: environment, operator: NorIn, values: [dev]} ``` - matchLabels用于定义一组Label,与直接写在Selector中作用相同 - matchExpression用于定义一组基于集合的筛选条件,可用的条件运算符包括:In、NotIn、Exists和DoesNotExist - 如果同时设置了matchLabels和matchExpression,则两组条件为“AND”关系,即所有条件需要满足才能完成Selector的筛选 ## 使用场景 - kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量始终符合预期设定 - kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的智能负载均衡机制 - 通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,kube-scheduler进程可以实现Pod“定向调度”的特性 # Annotation 注解 ## 概述 使用 Kubernetes Annotation(注解)为对象**附加任意的非标识的元数据自定义信息** 使用key/value键值对的形式进行定义 Map 中的**键和值必须是字符串**。也就是说,你不能使用数字、布尔值、列表或其他类型的键或值 ## 案例 以下是一些例子,用来说明哪些信息可以使用注解来记录: build信息、release信息、Docker镜像信息等,例如时间戳、release id号、PR号、镜像hash值、docker registry地址等。 日志库、监控库、分析库等资源库的地址信息。 程序调试工具信息,例如工具、版本号等。 团队等联系信息,例如电话号码、负责人名称、网址等。 例如,下面是一个 Pod 的配置文件,其注解中包含 imageregistry: https://www.orchome.com/: ``` apiVersion: v1 kind: Pod metadata: name: annotations-demo annotations: imageregistry: "https://www.orchome.com/" spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 ``` # RC 副本控制器(Replication Controller) ## 概述 Replication Controller(简称RC)是Kubernetes系统中的核心概念之一,简单来说,它其实是定义了一个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下几个部分。 - Pod期待的副本数(replicas)。 - 用于筛选目标Pod的Label Selector。 - 当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模版(template)。 下面是一个完整的RC定义的例子,即确保拥有tier=frontend标签的这个Pod(运行Tomcat容器)在整个Kubernetes集群中始终只有一个副本: ``` apiVersion: v1 kind: ReplicationController metadata: name: frontend spec: replicas: 1 selector: tier: frontend template: metadata: labels: app: app-demo tier: frontend spec: containers: - name: tomcat-demo image: tomcat imagePullPolicy: IfNotPresent env: - name: GET_HOSTS_FROM value: dns ports: - containerPort: 80 ``` 当我们定义了一个RC并提交到Kubernetes集群中以后,Master节点上的**Controller Manager组件**就得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值。 ## 动态扩缩容pod 在运行时,我们可以通过修改RC的副本数量,来实现Pod的动态缩放(Scaling)功能,还可以通过执行kubectl scale命令来一键完成: ``` kubectl scale rc redis-slave --replicas=3 ``` > redis-slave 是目标pod的name ## rc 清理 需要注意的是,删除RC并不会影响通过该RC已创建好的Pod。为了删除所有Pod,可以设置replicas的值为0,然后更新该RC。另外,kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod # RS 副本集(Replica Set) ## 概述 RS 是新一代 RC,提供同样的高可用能力,区别主要在于 RS 后来居上,能支持更多种类的匹配模式。副本集对象一般不单独使用,而是作为 Deployment 的理想状态参数使用。 ## 案例 ``` apiVersion: extensions/v1beta1 kind: ReplicaSet metadata: name: frontend spec: selector: matchLabels: tier: frontend matchExpression: - {key: tier, operator: In, values: [frontend]} template: ....... ``` ## RC 与 RS的对比 由于Replication Controller与Kubernetes代码中的模块Replication Controller同名,同时这个词也无法准确表达它的本意,所以在Kubernetes v1.2时,它就升级成了另外一个新的概念 -- Replica Set,官方解释为“下一代的RC”,它与RC当前存在的唯一区别是:Replica Sets支持基于集合的Label selector(Set-based selector),而RC只支持基于等式的Label Selector(equality-based selector),这使得Replica Set的功能更强 RS 很少单独使用,主要被**Deployment**这个更高层的资源对象所使用,从而形成一整套Pod创建、删除、更新的编排机制 Replica Set与Deployment这两个重要资源对象逐步替换了之前的RC的作用,是Kubernetes v1.3里Pod自动扩容(伸缩)这个告警功能实现的基础,也将继续在Kubernetes未来的版本中发挥重要的作用 ### 小结 总结一下关于RC(Replica Set)的一些特性与作用。 - 在大多数情况下,我们通过定义一个RC实现Pod的创建过程及副本数量的自动控制。 - RC里包括**完整的Pod定义模版**。 - RC**通过Label Selector机制**实现对Pod副本的自动控制。 - 通过改变RC里的Pod副本数量,可以实现**Pod的扩容或缩容功能**。 - 通过改变RC里的Pod模版中的**镜像版本**,可以实现Pod的**滚动升级功能**。 # Deployment 部署 ## 概述 Deployment是**Kubernetes v1.2引入的概念**,引入的目的是为了更好地**解决Pod的编排问题**。为此,Deployment在内部使用了Replica Set来实现目的,无论从Deployment的作用与目的,它的YAML定义,还是从它的具体命令行操作来看,我们都可以把它看作RC的一次升级,两者相似度超过90%。 Deployment相对于RC的一个最大升级是我们**随时知道当前Pod“部署”的进度**。实际上由于一个Pod的创建、调度、绑定节点及在目标Node上启动对应的容器这一完整过程需要一定的时间,所以我们期待系统启动N个Pod副本的目标状态,实际上是一个连续变化的“部署过程”导致的最终状态。 Deployment的典型使用场景有以下几个: - 创建一个Deployment对象来**生成对应的Replica Set并完成Pod副本的创建过程**。 - 检查Deployment的**状态**来看部署动作是否完成(Pod副本的数量是否达到预期的值)。 - **更新Deployment以创建新的Pod**(比如镜像升级)。 - 如果当前Deployment不稳定,则**回滚**到一个早先的Deployment版本。 - 暂停Deployment以便于一次性**修改**多个PodTemplateSpec的**配置项**,之后再恢复Deployment,进行新的发布。 - **扩展**Deployment以应对高负载。 - 查看Deployment的状态,以此作为发布是否成功的指标。 - 清理不再需要的旧版本ReplicaSets。 Deployment的定义与Replica Set的定义很类似,除了API声明与Kind类型等有所区别: ``` apiVersion: extensions/v1beta1 apiVersion: v1 kind: Deployment kind: ReplicaSet metadata: metadata: name: nginx-deployment name: nginx-repset ``` ## 案例 首先创建一个名为tomcat-deployment.yaml的Deployment描述文件,内容如下: ``` apiVersion: apps/v1 kind: Deployment metadata: name: tomcat-deploy spec: replicas: 1 selector: matchLabels: tier: tomcat-deploy matchExpressions: - {key: tier, operator: In, values: [frontend]} template: metadata: labels: app: app-demo tier: tomcat-deploy spec: containers: - name: tomcat-demo image: tomcat imagePullPolicy: IfNotPresent ports: - containerPort: 8080 ``` 运行下述命令创建Deploymeny: ``` # kubectl create -f tomcat-deployment.yaml deployment "tomcat-deploy" created ``` 运行下述命令查看Deployment的信息: ``` # kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE tomcat-deploy 1 1 1 1 4m ``` 对上述输出中涉及的数量解释如下: - DESIRED:Pod副本数量的期望值,即Deployment里定义的Replica。 - CURRENT:当前Replica的值,实际上是Deployment所创建的Replica Set里的Replica值,这个值不断增加,直到达到DESIRED为止,表明整个部署过程完成。 - UP-TO-DATE:最新版本的Pod副本数量,用于指示在滚动升级的过程中,有多少个Pod副本已经成功升级。 - AVAILABLE:当前集群中可用的Pod副本数量,即集群中当前可用的Pod数量。 运行下述命令查看对应的Replica Set,我们看到它的命名与Deployment的名字有关系: ``` # kubectl get rs NAME DESIRED CURRENT AGE tomcat-deploy-1640611518 1 1 1m ``` 运行下述命令查看创建的Pod,我们发现Pod的命名以Deployment对应的Replica Set的名字为前缀,这种命名很清晰地表明了一个Replica Set创建了哪些Pod,对于滚动升级这种复杂的过程来说,很容易排查错误: ``` # kubectl get pods NAME READY STATUS RESTARTS AGE tomcat-deploy-1640611518-zhrsc 1/1 Running 0 3m ``` # Service 服务 ## 概述 Service也是Kubernetes里的最核心的资源对象之一,Kubernetes里的每个Service其实就是我们经常提起的微服务架构中的一个“微服务”,之前我们所说的Pod、RC等资源对象其实都是为这节所说的“服务”------Kubernetes Service作“嫁衣”的。下图显示了Pod、RC与Service的逻辑关系。 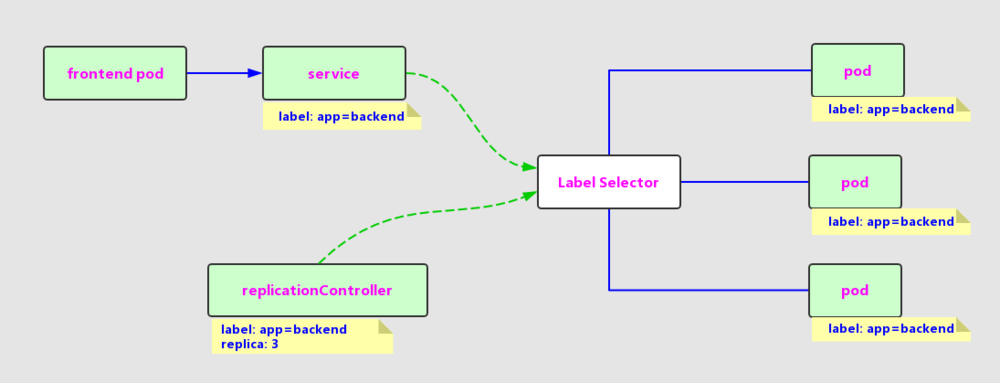 从图中我们看到,Kubernetes的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后的一组由Pod副本组成的集群实例,Service与其后端Pod副本集群之间则是通过Label Selector来实现“无缝对接”的。而RC的作用实际上是保证Service的服务能力和服务质量始终处于预期的标准。 既然每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立的Endpoint(Pod IP+ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务,那么客户端如何来访问它们呢?一般的做法是部署一个**负载均衡器**(软件或硬件),**为这组Pod开启一个对外的服务端口如8000端口**,并且将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端就可以通过负载均衡器的对外IP地址+服务端口来访问服务,而客户端的请求最后会被转发转发到哪个Pod,则由负载均衡器的算法所决定。 Kubernetes也遵循了上述常规做法,运行在每个**Node上的kube-proxy进程其实就是一个智能的软件负载均衡器**,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话机制。但Kubernetes发明了一种很巧妙又影响深远的设计:Service不是共用一个负载均衡的IP地址,而是**每个Service分配了全局唯一的虚拟IP地址**,这个虚拟IP地址被称为Cluster IP。这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。 我们知道,Pod的Endpoint地址会随着Pod的销毁和重新创建而发生改变,因为新Pod的IP地址与之前旧Pod的不同。而Service一旦被创建,Kubernetes就会自动为它分配一个可用的Cluster IP,而且在Service的整个生命周期内。它的Cluster IP不会发生改变。于是,**服务发现**这个棘手的问题在Kubernetes的架构里也得到轻松解决:只要**用Service的Name与Service的Cluster IP地址做一个DNS域名映射**即可完美解决问题。现在想想,这真是一个很棒的设计。 ## 案例 说了这么久,下面我们动手创建一个Service,来加深对它的理解。首先我们创建一个名为tomcat-service.yaml的定义文件,内容如下: ``` apiVersion: v1 kind: Service metadata: name: tomcat-service spec: ports: - port: 8080 selector: tier: frontend ``` 上述内容定义了一个名为“tomcat-service”的Service,它的服务端口为8080,拥有“tier-frontend”这个Label的所有Pod实例都属于它,运行下面的命令进行创建: ``` # kubectl create -f tomcat-service.yaml service "tomcat-service" created ``` 运行下面的命令可以查看tomcat-service的Endpoint列表,其中172.17.1.3是Pod的IP地址,端口8080是Container暴露的端口: ``` # kubectl get endpoints NAME ENDPOINTS AGE kubernetes 192.168.18.131:6443 15d tomcat-service 172.17.1.3:8080 1m ``` 运行下面的命令即可看到 tomcat-service 被分配的Cluster IP及更多的信息: ``` # kubectl get svc tomcat-service -o yaml apiVersion: v1 kind: Service metadata: creationTimestamp: 2018-10-17T10:04:21Z name: tomcat-service namespace: default resourceVersion: "10169415" selfLink: /api/v1/namespaces/default/services/tomcat-service uid: 04caf53f-d1f4-11e8-83a3-5254008f2a0b spec: clusterIP: 10.254.169.39 ports: - port: 8080 protocol: TCP targetPort: 8080 selector: tier: frontend sessionAffinity: None type: ClusterIP status: loadBalancer: {} ``` 在spec.ports的定义中,**targetPort属性用来确定提供该服务的容器所暴露(EXPOSE)的端口号**,即具体业务进程在容器内的targetPort上提供TCP/IP接入;而**port属性则定义了Service的虚拟端口**。前面我们定义Tomcat服务时,**没有指定targetPort,则默认targetPort与port相同**。 ## 多端口Service 很多服务都存在多个端口的问题,通常一个端口提供业务服务,另外一个端口提供管理服务,比如Mycat、Codis等常见中间件。Kubernetes Service支持多个Endpoint,在存在多个Endpoint的情况下,要求每个Endpoint定义一个名字区分。下面是Tomcat多端口的Service定义样例: ``` apiVersion: v1 kind: Service metadata: name: tomcat-service spec: ports: - port: 8080 name: service-port - port: 8005 name: shutdown-port selector: tier: frontend ``` 多端口为什么需要給每个端口命名呢?这就涉及Kubernetes的服务发现机制了,我们接下来进行讲解。 ## 服务发现机制 任何分布式系统都会涉及“服务发现”这个基础问题,大部分分布式系统通过提供特定的API接口来实现服务发现的功能,但这样做会导致平台的入侵性比较强,也增加了开发测试的困难。Kubernetes则采用了直观朴素的思路去解决这个棘手的问题。 首先,每个Kubernetes中的Service都有一个唯一的Cluster IP及唯一的名字,而名字是由开发者自己定义的,部署时也没有改变,所以完全可以固定在配置中。接下来的问题就是如何通过Service的名字找到对应的Cluster IP? 最早时Kubernetes采用了Linux环境变量的方式解决这个问题,即每个Service生成一些对应的Linux环境变量(ENV),并在每个Pod的容器在启动时,自动注入这些环境变量,以下是tomcat-service产生的环境变量条目: ``` TOMCAT_SERVICE_SERVICE_HOST=10.254.93.4 TOMCAT_SERVICE_SERVICE_PORT_SERVICE_PORT=8080 TOMCAT_SERVICE_SERVICE_PORT_SHUTDOWN_PORT=8005 TOMCAT_SERVICE_SERVICE_PORT=8080 TOMCAT_SERVICE_PORT=tcp://10.254.93.4:8080 TOMCAT_SERVICE_PORT_8080_TCP_ADDR=10.254.93.4 TOMCAT_SERVICE_PORT_8080_TCP=tcp://10.254.93.4:8080 TOMCAT_SERVICE_PORT_8080_TCP_PROTO=tcp TOMCAT_SERVICE_PORT_8080_TCP_PORT=8080 TOMCAT_SERVICE_PORT_8005_TCP=tcp://10.254.93.4:8005 TOMCAT_SERVICE_PORT_8005_TCP_ADDR=10.254.93.4 TOMCAT_SERVICE_PORT_8005_TCP_PROTO=tcp TOMCAT_SERVICE_PORT_8005_TCP_PORT=8005 ``` 上述环境变量中,比较重要的是前3条环境变量,我们可以看到,每个Service的IP地址及端口都是有标准的命名规范,就可以通过代码访问系统环境变量的方式得到所需的信息,实现服务调用。 考虑到环境变量的方式获取Service的IP与端口的方式仍然不太方便,不够直观,后来Kubernetes通过Add-On增值包的方式引入了DNS系统,把服务名作为dns域名,这样一来,程序就可以直接使用服务名来建立通信连接了。目前Kubernetes上的大部分应用都已经采用了DNS这些新型的服务发现机制,后面的章节中我们会讲述如何部署这套DNS系统。 ## 外部系统访问Service的问题 为了更好深入地理解和掌握Kubernetes,我们需要弄明白Kubernetes里的“三种IP”这个关键问题,这三种分别如下: ``` Node IP:Node节点的IP地址。 Pod IP:Pod的IP地址。 Cluster IP:Service的IP地址。 ``` 首先,**Node IP**是Kubernetes集群中每个**节点的物理网卡的IP地址**,这是一个**真实存在的物理网络**,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个Kubernetes集群。这也表明了Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务时,必须要通过Node IP进行通信。 其次,**Pod IP**是每个**Pod的IP地址**,它是**Docker Engine根据docker0网桥的IP地址段进行分配的**,通常是一个**虚拟的二层网络**,前面我们说过,Kubernetes里一个Pod里的容器访问另外一个Pod里的容器,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。 最后,我们说说Service的**Cluster IP**,它也是一个**虚拟的IP**,但更像是一个“伪造”的IP网络,原因有以下几点: - Cluster IP**仅仅作用于Kubernetes Service这个对象**,并由Kubernetes管理和分配IP地址(来源于Cluster IP地址池)。 - Cluster IP无法被Ping,因为没有一个“实体网络对象”来响应。 - **Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于Kubernetes集群这样一个封闭的空间,集群之外的节点如果要访问这个通信端口,则需要做一些额外的工作**。 - 在Kubernetes集群之内,Node IP网、Pod IP网与Clsuter IP之间的通信,采用的是Kubernetes自己设计的一种编程方式的特殊的路由规则,与我们所熟知的IP路由有很大的不同。 根据上面的分析和总结,我们基本明白了:Service的Cluster IP属于Kubernetes集群内部的地址,无法在集群外部直接使用这个地址。那么矛盾来了:**实际上我们开发的业务系统中肯定多少由一部分服务是要提供給Kubernetes集群外部的应用或者用户来使用的,典型的例子就是Web端的服务模块,比如上面的tomcat-service,那么用户怎么访问它?** 采用**NodePort是解决上述问题的最直接、最常用的做法**。具体做法如下,以tomcat-service为例,我们在Service的定义里做如下扩展即可(黑体字部分): ``` apiVersion: v1 kind: Service metadata: name: tomcat-service spec: type: NodePort ports: - port: 8080 nodePort: 31002 selector: tier: frontend ``` 其中,```nodePort:31002```这个属性表明我们手动指定tomcat-service的NodePort为31002,否则Kubernetes会自动分配一个可用的端口。接下来,我们在浏览器里访问https://<nodePort IP>:31002,就可以看到Tomcat的欢迎界面了,如图所示。  NodePort的实现方式是在Kubernetes集群里的每个Node上为需要外部访问的Service开启一个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址+具体的NodePort端口号即可访问此服务,在任意Node上运行netstat命令,我们就可以看到有NodePort端口被监听: ``` # netstat -tlp|grep 31002 tcp6 0 0 [::]:31002 [::]:* LISTEN 19043/kube-proxy ``` 但NodePort还没有完全解决外部访问Service的所有问题,比如负载均衡问题,假如我们的集群中有10个Node,则此时最好有一个负载均衡器,外部的请求只需要访问此负载均衡器的IP地址,由负载均衡负责转发流量到后面某个Node的NodePort上。如图所示。 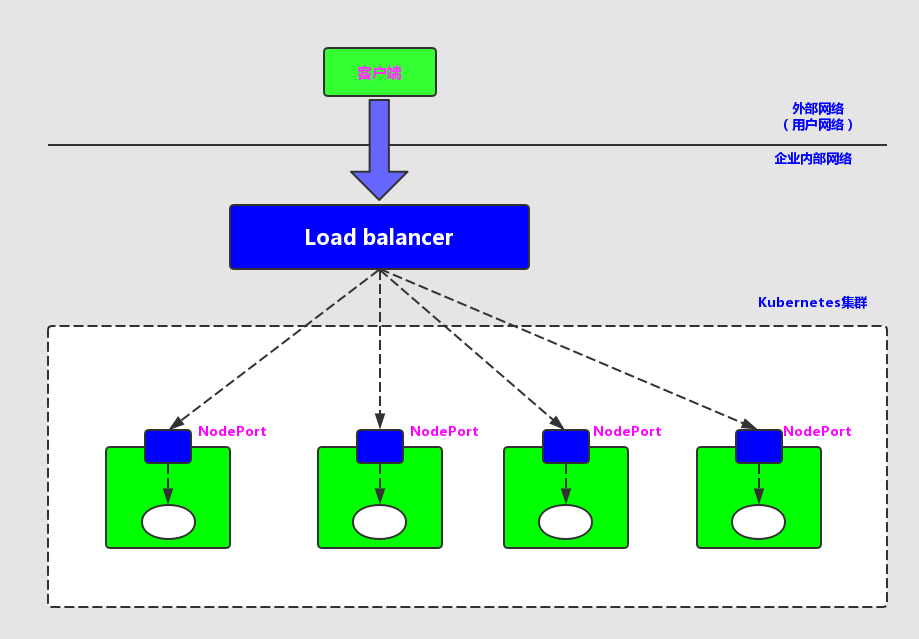 图中的Load balancer组件独立于Kubernetes集群之外,通常是一个硬件的负载均衡器,或者是以软件方式实现的,例如HAProxy或者Nginx。对于每个Service,我们通常需要配置一个对应的Load balancer实例来转发流量到后端的Node上,这的确增加了工作量及出错的概率。于是**Kubernetes提供了自动化的解决方案**,如果我们的集群运行在**谷歌的GCE公有云上,那么只要我们把Service的type=NodePort改为type=LoadBalancer,此时Kubernetes会自动创建一个对应的Load balancer实例并返回它的IP地址供外部客户端使用。其他公有云提供商只要实现了支持此特性的驱动,则也可以达到上述目的。此外,裸机上的类似机制(Bare Metal Service Load Balancers)也正在被开发**。 # Job 任务 Job 是 Kubernetes 用来控制批处理型任务的 API 对象。 类比Linux的cron定时任务 # DaemonSet 后台支撑服务集 后台支撑型服务的核心关注点在 Kubernetes 集群中的节点(物理机或虚拟机),要保证每个节点上都有一个此类 Pod 运行。 典型的后台支撑型服务包括,存储,日志和监控等在每个节点上支持 Kubernetes 集群运行的服务。 # StatefulSet 有状态服务集 ## 概述 在Kubernetes系统中,Pod的管理对象RC、Deployment、DaemonSet和Job都是面向无状态的服务。但现实中有很多服务是有状态的,特别是一些复杂的中间件集群,例如MySQL集群、MongoDB集群、Kafka集群、Zookeeper集群等。 StatefulSet从本质上来说,可以看作 Deployment/RC 的一个特殊变种,它有如下一些特性: - StatefulSet里的每个Pod都有**稳定、唯一的网络标识**,可以用来发现集群内的其他成员。假设StatefulSet的名字叫kafka,那么第一个Pod叫kafak-0,第二个Pod叫kafak-1,第三个叫kafka-2,以此类推 - StatefulSet控制的**Pod副本的启停顺序是受控的**,操作第n个Pod时,前n-1个Pod已经时运行且准备好的状态 - StatefulSet里的Pod采用**稳定的持久化存储卷**,通过 PV/PVC 来实现,删除Pod时默认不会删除与StatefulSet相关的存储卷(为了保证数据的安全) ## StatefulSet 与 headless service (无头服务) StatefulSet除了要与PV卷捆绑使用以存储Pod的状态数据,还要**与Headless Service(无头服务)配合使用**,即在每个StatefulSet的定义中要声明它**属于哪个Headless Service**。**Headless Service与普通Service的关键区别**在于,它**没有Cluster IP**,如果解析Headless Service的DNS域名,则返回的是该Service对应的全部Pod的Endpoint列表。StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod实例创建了一个DNS域名,这个域名的格式为: ``` $(podname).$(headless service name) ``` 比如一个3节点的 StatefulSet 集群,对应的 Headless Service 的名字为nginx,StatefulSet的名字为web,则 StatefulSet 里面的 3 个 Pod 的 DNS 名称分别为web-0.nginx、web-1.nginx、web-2.nginx,这些DNS名称可以直接在集群的配置文件中固定下来。 ### 示例 ``` kind: Service metadata: name: nginx labels: app: nginx spec: ports: - port: 80 name: web clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: web spec: selector: matchLabels: app: nginx # 必须匹配 .spec.template.metadata.labels serviceName: "nginx" replicas: 3 # 默认值是 1 minReadySeconds: 10 # 默认值是 0 template: metadata: labels: app: nginx # 必须匹配 .spec.selector.matchLabels spec: terminationGracePeriodSeconds: 10 containers: - name: nginx image: registry.k8s.io/nginx-slim:0.8 ports: - containerPort: 80 name: web volumeMounts: - name: www mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: www spec: accessModes: [ "ReadWriteOnce" ] storageClassName: "my-storage-class" resources: requests: storage: 1Gi ``` 上述例子中: - 名为 nginx 的 Headless Service 用来控制网络域名。 - volumeClaimTemplates 提供存储。 ## 部署和扩缩保证 - 对于包含 N 个 副本的 StatefulSet,当部署 Pod 时,它们是依次创建的,顺序为 0..N-1。 - 当删除 Pod 时,它们是逆序终止的,顺序为 N-1..0。 - 在将扩缩操作应用到 Pod 之前,它前面的所有 Pod 必须是 Running 和 Ready 状态。 - 在一个 Pod 终止之前,所有的继任者必须完全关闭。 StatefulSet 不应将 ```pod.Spec.TerminationGracePeriodSeconds``` 设置为 0。 这种做法是不安全的。 > 详细过程: 在上面的 nginx 示例被创建后,会按照 web-0、web-1、web-2 的顺序部署三个 Pod。 在 web-0 进入 Running 和 Ready 状态前不会部署 web-1。在 web-1 进入 Running 和 Ready 状态前不会部署 web-2。 如果 web-1 已经处于 Running 和 Ready 状态,而 web-2 尚未部署,在此期间发生了 web-0 运行失败,那么 web-2 将不会被部署,要等到 web-0 部署完成并进入 Running 和 Ready 状态后,才会部署 web-2。 如果用户想将示例中的 StatefulSet 扩缩为 replicas=1,首先被终止的是 web-2。 在 web-2 没有被完全停止和删除前,web-1 不会被终止。 当 web-2 已被终止和删除、web-1 尚未被终止,如果在此期间发生 web-0 运行失败, 那么就不会终止 web-1,必须等到 web-0 进入 Running 和 Ready 状态后才会终止 web-1。 ## Pod 管理策略 StatefulSet 允许你放宽其排序保证,通过 .spec.podManagementPolicy 来设置。 - 顺序 Pod 管理 - ```podManagementPolicy: "OrderedReady"``` 是默认设置。它保证了Pod顺序。 - 并行 Pod 管理 - ```podManagementPolicy: "Parallel"``` 让 StatefulSet 控制器并行的启动或终止所有的 Pod,启动或者终止其他 Pod 前,无需等待 Pod 进入 Running 和 ready 或者完全停止状态。 这个选项只会影响扩缩操作的行为,更新不会被影响。 ## 更新策略 StatefulSet 的 ```.spec.updateStrategy``` 字段让你可以配置和禁用掉自动滚动更新 Pod 的容器、标签、资源请求或限制、以及注解。有两个允许的值: - OnDelete - 当 StatefulSet 的 ```.spec.updateStrategy.type``` 设置为 OnDelete 时, 它的控制器将不会自动更新 StatefulSet 中的 Pod。 用户必须手动删除 Pod 以便让控制器创建新的 Pod。 - RollingUpdate - RollingUpdate 更新策略对 StatefulSet 中的 Pod 执行自动的滚动更新。这是默认的更新策略。 ## 最大不可用 Pod 特性状态: Kubernetes v1.24 你可以通过指定 ```.spec.updateStrategy.rollingUpdate.maxUnavailable``` 字段来控制更新期间不可用的 Pod 的最大数量。 该值可以是绝对值(例如,“5”)或者是期望 Pod 个数的百分比(例如,10%)。 绝对值是根据百分比值四舍五入计算的。 该字段不能为 0。默认设置为 1。 该字段适用于 0 到 replicas - 1 范围内的所有 Pod。 如果在 0 到 replicas - 1 范围内存在不可用 Pod,这类 Pod 将被计入 maxUnavailable 值。 ## 更多 https://www.orchome.com/16675 # Volume 存储卷 ## 概述 Kubernetes的Volume概念、用途和目的与Docker的Volume比较类似,但两者不能等价。 首先,Kubernetes中的Volume定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下; 其次,Kubernetes中的Volume中的数据也不会丢失。 最后,Kubernetes支持多种类型的Volume,例如Gluster、Ceph等先进的分布式文件系统。 ## 示例demo 举例来说,我们要給之前的Tomcat Pod增加一个名字为```datavol```的**Volume**,并且Mount到容器的```/mydata-data```目录上: ``` template: metadata: labels: app: app-demo tier: frontend spec: volumes: - name: datavol emptyDir: {} containers: - name: tomcat-demo image: tomcat imagePullPolicy: IfNotPersent volumeMounts: - mountPath: /mydata-data name: datavol ``` 除了可以让一个Pod里的**多个容器共享文件**、**让容器的数据写到宿主机的磁盘上或者写文件到网络存储中**,Kubernetes的Volume还扩展出了一种**非常有实用价值的功能**,即**容器配置文件集中化定义与管理**,这是通过ConfigMap这个新的资源对象来实现的,后面我们会详细说明。 Kubernetes提供了非常丰富的Volume类型,下面逐一进行说明。 ## EmptyDir 一个emptyDir Volume是**在Pod分配到Node时创建**的。从它的名称就可以看出,它的**初始内容为空**,并且无须指定宿主机上对应的目录文件,因为这是Kubernetes自动分配的一个目录,当**Pod从Node上移除时,emptyDir中的数据也会被永久删除**。empty的一些用途如下: - **临时空间**,例如用于某些应用程序运行时所需的临时目录,且无须永久保留。 - 长时间任务的中间过程CheckPoint的**临时保存目录**。 - 一个容器需要从另一个容器中获取数据的目录(**多容器共享目录**)。 目前,用户无法控制emptyDir使用的介质种类。如果kubelet的配置是使用硬盘,那么所有emptyDir都将创建在该硬盘上。Pod在将来可以设置emptyDir是位于硬盘、固态硬盘上还是基于内存的tmpfs上,上面的例子便采用了emptyDir类的Volume。 **缺省情况下,EmptyDir 是使用主机磁盘进行存储的**,也可以**设置emptyDir.medium 字段的值为Memory**,来**提高运行速度**,但是这种设置,对该卷的占用**会消耗容器的内存份额**。 ## hostPath **hostPath**为在**Pod上挂载宿主机上的文件或目录**,它通常可以用于以下几方面: - 容器应用程序生成的日志文件需要永久保持时,可以使用宿主机的高速文件系统进行存储。 - 需要访问宿主机上Docker引擎内部数据结构的容器应用时,可以通过定义hostPath为宿主机/var/lib/docker目录,使容器内部应用可以直接访问Docker的文件系统。 在使用这种类型的Volume时,需要注意以下几点: - 在不同的Node上具有相同配置的Pod可能会因为宿主机上的目录和文件不同而导致对Volume上目录和文件的访问结构不一致。 - 如果使用了资源配额管理,则Kubernetes无法将hostPath在宿主机上使用的资源纳入管理。 在下面对例子中使用宿主机的/data目录定义了一个hostPath类型的Volume: ``` volumes: - name: "persistent-storage" hostPath: path: "/data" ``` ## NFS 使用NFS网络文件系统提供的共享目录存储数据时,我们需要在系统中[部署一个NFS Server](http://gyfblog.com/article/99/ "部署一个NFS Server")。定义NFS类型的Volume的示例如下: ``` volumes: - name: nfs nfs: # 改为你的NFS服务器地址 server: nfs-server.localhost path: "/" ``` # PV & PVC 持久存储卷(Persistent Volume)和持久存储卷声明(Persistent Volume Claim)  ## 概述 **管理存储**和**管理计算**有着明显的不同。**PersistentVolume**给用户和管理员**提供了一套API**,抽象出存储是如何提供和消耗的细节。在这里,我们介绍两种**新的API资源**:**PersistentVolume**(简称PV)和**PersistentVolumeClaim**(简称PVC)。 - **PersistentVolume**(持久卷,简称PV)是集群内,由管理员提供的**网络存储**的一部分。就像集群中的节点一样,PV也是集群中的一种资源。它也像Volume一样,是一种volume插件,但是**它的生命周期却是和使用它的Pod相互独立的**。PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节。 - **PersistentVolumeClaim**(持久卷声明,简称PVC)是用户的一种**存储请求**。它和Pod类似,Pod消耗Node资源,而**PVC消耗PV资源**。Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式(可以被映射为一次读写或者多次只读)。 **PVC允许用户消耗抽象的存储资源**,用户也经常需要各种属性(如性能)的PV。集群管理员需要提供各种各样、不同大小、不同访问模式的PV,而不用向用户暴露这些volume如何实现的细节。因为这种需求,就催生出一种**StorageClass资源**。 **StorageClass**提供了一种方式,使得管理员能够描述他提供的存储的等级。集群管理员可以将不同的等级映射到不同的服务等级、不同的后端策略。 ## PV 和 PVC 的区别 **PersistentVolume(持久卷)**和**PersistentVolumeClaim(持久卷申请)**是k8s提供的**两种API资源**,用于**抽象存储细节**。管理员关注于如何通过pv提供存储功能而无需关注用户如何使用,同样的用户只需要挂载pvc到容器中而不需要关注存储卷采用何种技术实现。 **pvc和pv的关系与pod和node关系类似,前者消耗后者的资源**。pvc可以向pv申请指定大小的存储资源并设置访问模式,这就可以通过Provision -> Claim 的方式,来对存储资源进行控制。 ## volume和claim的生命周期 PV是集群中的资源,PVC是对这些资源的请求,同时也是这些资源的“提取证”。PV和PVC的交互遵循以下生命周期: - **供给** - 有两种PV提供的方式:静态和动态。 - **静态** - 集群管理员创建多个PV,它们携带着真实存储的详细信息,这些存储对于集群用户是可用的。它们存在于Kubernetes API中,并可用于存储使用。 - **动态** - 当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass:PVC必须请求这样一个等级,而管理员必须已经创建和配置过这样一个等级,以备发生这种动态供给的情况。请求等级配置为“”的PVC,有效地禁用了它自身的动态供给功能。 - **绑定** - 用户创建一个PVC(或者之前就已经就为动态供给创建了),指定要求存储的大小和访问模式。master中有一个控制回路用于监控新的PVC,查找匹配的PV(如果有),并把PVC和PV绑定在一起。如果一个PV曾经动态供给到了一个新的PVC,那么这个回路会一直绑定这个PV和PVC。另外,用户总是至少能得到它们所要求的存储,但是volume可能超过它们的请求。一旦绑定了,PVC绑定就是专属的,无论它们的绑定模式是什么。 - 如果没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态,一旦PV可用了,PVC就会又变成绑定状态。比如,如果一个供给了很多50G的PV集群,不会匹配要求100G的PVC。直到100G的PV添加到该集群时,PVC才会被绑定。 - **使用** - Pod使用PVC就像使用volume一样。集群检查PVC,查找绑定的PV,并映射PV给Pod。对于支持多种访问模式的PV,用户可以指定想用的模式。一旦用户拥有了一个PVC,并且PVC被绑定,那么只要用户还需要,PV就一直属于这个用户。用户调度Pod,通过在Pod的volume块中包含PVC来访问PV。 - **释放** - 当用户使用PV完毕后,他们可以通过API来删除PVC对象。当PVC被删除后,对应的PV就被认为是已经是“released”了,但还不能再给另外一个PVC使用。前一个PVC的属于还存在于该PV中,必须根据策略来处理掉。 - **回收** - PV的回收策略告诉集群,在PV被释放之后集群应该如何处理该PV。当前,PV可以被Retained(保留)、 Recycled(再利用)或者Deleted(删除)。保留允许手动地再次声明资源。对于支持删除操作的PV卷,删除操作会从Kubernetes中移除PV对象,还有对应的外部存储(如AWS EBS,GCE PD,Azure Disk,或者Cinder volume)。动态供给的卷总是会被删除 ## Recycled(再利用) 如果PV卷支持再利用,再利用会在PV卷上执行一个**基础的擦除操作**(rm -rf /thevolume/*),使得它可以再次被其他PVC声明利用。 管理员可以通过Kubernetes controller manager的命令行工具,来配置自定义的再利用Pod模板。**自定义的再利用Pod模板**必须包含PV卷的详细内容,如下示例: ``` apiVersion: v1 kind: Pod metadata: name: pv-recycler- namespace: default spec: restartPolicy: Never volumes: - name: vol hostPath: path: /any/path/it/will/be/replaced containers: - name: pv-recycler image: "gcr.io/google_containers/busybox" command: ["/bin/sh", "-c", "test -e /scrub && rm -rf /scrub/..?* /scrub/.[!.]* /scrub/* && test -z \"$(ls -A /scrub)\" || exit 1"] volumeMounts: - name: vol mountPath: /scrub ``` 如上,在volumes部分的指定路径,应该被替换为PV卷需要再利用的路径。 ## PV 类型 PV类型使用插件的形式来实现。Kubernetes现在支持以下插件: - GCEPersistentDisk - AWSElasticBlockStore - AzureFile - AzureDisk - FC (Fibre Channel) - Flocker - NFS - iSCSI - RBD (Ceph Block Device) - CephFS - Cinder (OpenStack block storage) - Glusterfs - VsphereVolume - Quobyte Volumes - HostPath (仅测试过单节点的情况——不支持任何形式的本地存储,多节点集群中不能工作) - VMware Photon - Portworx Volumes - ScaleIO Volumes ## PV 定义yaml 每个PV都包含一个spec和状态,即说明书和PV卷的状态。 ``` apiVersion: v1 kind: PersistentVolume metadata: name: pv0003 spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle storageClassName: slow nfs: path: /tmp server: 172.17.0.2 ``` ## PVC 定义yaml ``` kind: PersistentVolumeClaim apiVersion: v1 metadata: name: myclaim spec: accessModes: - ReadWriteOnce resources: requests: storage: 8Gi storageClassName: slow selector: matchLabels: release: "stable" matchExpressions: - {key: environment, operator: In, values: [dev]} ``` ## pod 使用 PVC Pod通过使用PVC(使用方式和volume一样)来访问存储。PVC必须和使用它的pod在同一个命名空间,集群发现pod命名空间的PVC,根据PVC得到其后端的PV,然后PV被映射到host中,再提供给pod。 ``` kind: Pod apiVersion: v1 metadata: name: mypod spec: containers: - name: myfrontend image: dockerfile/nginx volumeMounts: - mountPath: "/var/www/html" name: mypd volumes: - name: mypd persistentVolumeClaim: claimName: myclaim ``` ## 选择器(Selector) PVC可以指定标签选择器进行更深度的过滤PV,只有匹配了选择器标签的PV才能绑定给PVC。选择器包含两个字段: - matchLabels(匹配标签) - PV必须有一个包含该值得标签 - matchExpressions(匹配表达式) - 一个请求列表,包含指定的键、值的列表、关联键和值的操作符。合法的操作符包含In,NotIn,Exists,和DoesNotExist。 所有来自matchLabels和matchExpressions的请求,都是逻辑与关系的,它们必须全部满足才能匹配上。 ## 访问模式 访问模式包括: - ReadWriteOnce -- 该volume只能被单个节点以读写的方式映射 - ReadOnlyMany -- 该volume可以被多个节点以只读方式映射 - ReadWriteMany -- 该volume只能被多个节点以读写的方式映射 在CLI中,访问模式可以简写为: - RWO - ReadWriteOnce - ROX - ReadOnlyMany - RWX - ReadWriteMany ## 等级 Class ### PV 与 class 一个PV可以有一种class,通过设置```storageClassName```属性来选择指定的```StorageClass```。 有指定class的PV只能绑定给请求该class的PVC。 没有设置storageClassName属性的PV只能绑定给未请求class的PVC。 ### PVC 与 class PVC可以使用属性```storageClassName```来指定StorageClass的名称,从而请求指定的等级。只有满足请求等级的PV,即那些包含了和PVC相同storageClassName的PV,才能与PVC绑定。 **PVC并非必须要请求一个等级class**。 设置```storageClassName```为```""```的PVC被理解为请求一个**无等级的PV**,因此它只能被绑定到无等级的PV(未设置对应的标注,或者设置为“”)。 **未设置storageClassName的PVC**不太相同,**DefaultStorageClass**的**权限插件打开与否**,集群也会**区别处理PVC**: - 如果**权限插件被打开**: - 管理员若**指定一个默认的StorageClass**。**则所有没有指定StorageClassName的PVC只能被绑定到默认等级的PV**。 - 如果管理员没有指定这个默认值,集群对PVC创建请求的回应就和**权限插件被关闭**时一样。如果指定了多个默认等级,那么权限插件禁止PVC创建请求。 - 要**指定默认的StorageClass**,需要在**StorageClass对象**中将标注```storageclass.kubernetes.io/is-default-class```设置为```"true"```。 - 如果**权限插件被关闭**:那么就没有默认StorageClass的概念。所有没有设置StorageClassName的PVC都只能绑定到没有等级的PV。因此,没有设置StorageClassName的PVC就如同设置StorageClassName为```""```的PVC一样被对待。 > 注意:根据安装方法的不同,默认的StorageClass可能会在安装过程中被插件管理默认的部署在Kubernetes集群中。 过去,使用```volume.beta.kubernetes.io/storage-class```注解,而不是storageClassName属性。该注解现在依然可以工作,但在Kubernetes的未来版本中已经被完全弃用了。 ## StorageClass 每个StorageClass都包含字段provisioner和parameters,在所属的PV需要动态供给时使用这些字段。 StorageClass对象的命名是非常重要的,它是用户请求指定等级的方式。当创建StorageClass对象时,管理员设置等级的名称和其他参数,但对象不会在创建后马上就被更新。 管理员可以指定一个默认的StorageClass,用于绑定到那些未请求指定等级的PVC。 ## 回收策略 当前的回收策略有: - Retain:手动回收 - Recycle:需要擦出后才能再使用 - Delete:相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除 当前,只有NFS和HostPath支持回收利用,AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷支持删除操作。 ## Volume 阶段 一个volume卷处于以下几个阶段之一: - Available:空闲的资源,未绑定给PVC - Bound:绑定给了某个PVC - Released:PVC已经删除了,但是PV还没有被集群回收 - Failed:PV在自动回收中失败了 # Node 节点 Kubernetes 集群中的计算能力由 Node 提供,最初 Node 称为服务节点 Minion,后来改名为 Node。Kubernetes 集群中的 Node 也就等同于 Mesos 集群中的 Slave 节点,是所有 Pod 运行所在的工作主机,可以是物理机也可以是虚拟机。不论是物理机还是虚拟机,工作主机的统一特征是上面要运行 kubelet 管理节点上运行的容器。 # Secret 密钥对象 Secret 是用来保存和传递密码、密钥、认证凭证这些敏感信息的对象。使用 Secret 的好处是可以避免把敏感信息明文写在配置文件里。在 Kubernetes 集群中配置和使用服务不可避免的要用到各种敏感信息实现登录、认证等功能,例如访问 AWS 存储的用户名密码。为了避免将类似的敏感信息明文写在所有需要使用的配置文件中,可以**将这些信息存入一个 Secret 对象,而在配置文件中通过 Secret 对象引用这些敏感信息。这种方式的好处包括:意图明确,避免重复,减少暴漏机会**。 # 用户帐户(User Account)和服务帐户(Service Account) 顾名思义,用户帐户为人提供账户标识,而服务账户为计算机进程和 Kubernetes 集群中运行的 Pod 提供账户标识。用户帐户和服务帐户的一个区别是作用范围;用户帐户对应的是人的身份,人的身份与服务的 namespace 无关,所以用户账户是跨 namespace 的;而服务帐户对应的是一个运行中程序的身份,与特定 namespace 是相关的。 # Namespace 命名空间 ## 概述 Namespace(命名空间)是Kubernetes系统中的另一个非常重要的概念,Namespace在很多情况下用于实现多租户的资源隔离。Nameaspace通过将集群内部的资源对象“分配”到不同的Namespce中,形成逻辑上分组的不同项目、小组或用户组,便于不同的分组在共享使用整个集群的资源的同时还能被分别管理。 Kubernetes集群在启动后,会创建一个名为“default”的Namespace,通过kubectl可以查看到: ``` $ kubectl get namespaces NAME STATUS AGE default Active 21h docker Active 21h kube-public Active 21h kube-system Active 21h ``` 简写形式,将namespace缩写为ns: ``` kubectl get ns ``` > 注意,如果不特别指明Namespace,则用户创建的Pod、RC、Service都被系统创建到这个默认的名为default的Namespace中。 ## ns 定义yaml Namespace的定义很简单,如下所示的yaml定义了名为development的Namespace: ``` apiVersion: v1 kind: Namespace metadata: name: development ``` 命令形式创建Namespace: ``` kubectl create ns development ``` 一旦创建了Namespace,我们在创建资源对象时就可以指定这个资源对象属于哪个Namespace。比如在下面的例子中,我们定义了一个名为busybox的Pod,放人development这个Namespace里: ``` apiVersion: v1 kind: Pod metadata: name: busybox namespace: development spec: containers: - image: busybox command: - sleep - "3600" name: busybox ``` 此时,使用kubectl get命令查看将无法显示: ``` # kubectl get pods NAME READY STATUS RESTARTS AGE ``` 这是因为如果不加参数,则 kubectl get 命令将仅显示属于“default”命名空间的资源对象。 可以在kubectl命令中加入--namespace参数来查看某个命名空间中的对象: ``` # kubectl get pods --namespace=development NAME READY STATUS RESTARTS AGE busybox 1/1 Running 0 2m ``` 缩写形式 ``` kubectl get pods -n development ``` 最后,删除这个Namespace: ``` kubectl delete ns development ``` ## 多租户资源配额管理 当我们給每个租户创建一个Namespace来实现多租户的资源隔离时,还能结合Kubernetes的资源配额管理,限定不同租户能占用的资源,例如CPU使用量、内存使用量等。 # RBAC 访问授权 基于角色的访问控制(Role-based Access Control,RBAC)的授权模式,RBAC 主要是引入了角色(Role)和角色绑定(RoleBinding)的抽象概念。 # 总结 从 Kubernetes 的系统架构、技术概念和设计理念,我们可以看到 Kubernetes 系统最核心的两个设计理念:一个是 容错性,一个是 易扩展性。容错性实际是保证 Kubernetes 系统稳定性和安全性的基础,易扩展性是保证 Kubernetes 对变更友好,可以快速迭代增加新功能的基础。 参考: https://lib.jimmysong.io/kubernetes-handbook/architecture/perspective/ https://www.orchome.com/1337
0
0
上一篇:K8s 学习资料汇总
下一篇:K8s yaml 语法
你觉得文章怎么样
发布评论

342 人参与,0 条评论